






Apache Solr is a subproject of Apache Lucene, which is the indexing technology behind most recently created search and index technology. Solr is a search engine at heart, but it is much more than that. It is a NoSQL database with transactional support. It is a document database that offers SQL support and executes it in a distributed manner.
Sound interesting? Join me for a closer look. (Full disclosure: I work for Lucidworks, which employs many of the key contributors to the Solr project.)
You need a decent machine (or just use an AWS instance) with ideally 8GB or more RAM. You can find Solr at http://lucene.apache.org/solr. You also need the Java Virtual Machine version 8. Unzip/untar Solr into a directory, make sure JAVA_HOME is set, and that the java binary is in your path. Change to the directory Solr is in and type bin/solr start -e cloud -noprompt. This starts a two node cluster on your laptop with a sample collection called gettingstarted already loaded.
A normal startup would just be bin/solr start -c to start Solr in “cloud” mode. But if you’re going to kick the tires you really want to see a multi-node install even if it is on your own laptop. Solr Cloud is the way you want to run a modern Solr install. If you start without the -c you’ll start in legacy mode. That is a bad thing.
Documents and collections
Solr is a document structured database. Entities like “Person” are composed of fields like name, address, and email. Those documents are stored in collections. Collections are the closest analog to tables in a relational database. However, unlike in a relational database, “Person” can completely contain the entity, meaning if a person has multiple addresses those addresses can be stored in one “Person” document. In a relational database you’d need a separate addresses table.
Person {
"Id": "1333425",
“first_name”: “Francis”,
“middle_name”: “J.”,
“last_name”: “Underwood”,
“address”: [“1600 Pennsylvania Ave NW, Washington, DC 20500”, “1609 Far St. NW, Washington, D.C., 20036”],
“phone”: [“202-456-1111”, “202-456-1414”]
}Shards, replicas, and cores
Unlike in most relational databases, data is automatically sharded and replicated via Solr Cloud. This means that when you write a document to a properly configured collection it is distributed to one of the Solr instances. That’s “sharding.” It is done to improve read performance. Each document is also replicated or copied at least once (configurable) for redundancy. This means you can lose a Solr instance and suffer only reduced performance across your cluster, but no data loss.
A cluster is a set of “nodes,” which are Java Virtual Machine (JVM) instances running Solr. A node can contain multiple “cores.” Each core is a replica of a logical “shard.” Generally cores are identified by the collection, shard number, and replica number concatenated together as a string.
Creating a collection
Although there are REST-like HTTP interfaces, you can just use the bin/solr (or bin/solr.cmd) command to create and control collections. Let’s use a non-controversial topic and find a public dataset. Grab a copy of healthcare cost data from Data.gov. For simplicity’s sake grab it as a CSV. Assuming you started Solr as directed, use this command to create a collection called ipps:
bin/solr create_collection -d basic_configs -c ipps
Next let’s load data into the collection. First we need to fix a few things in the CSV file. Remove all of the $ characters. Also, in the top row of field names, change the fields from spaces to underscores. Make it read like this:
DRG_Definition,Provider_Id,Provider_Name,Provider_Street_Address,Provider_City,Provider_State,Provider_Zip_Code,Hospital_Referral_Region_Description,Total_Discharges,Average_Covered_Charges,Average_Total_Payments,Average_Medicare_Payments
There are more powerful tools for ETL than what are built in to Solr (such as the one built into the product my company sells), but overall this wasn’t a complicated fix!
Before we load any data though we need to create a “schema” which is similar to what you have in a relational database. We can do that with the curl command on Linux/Mac or you can use a GUI tool like Postman.
curl -X POST -H ‘Content-type:application/json’ —data-binary ‘{
“add-field”:{
“name”:”DRG_Definition”,
“type”:”text_general”,
“indexed”:true,
“stored”:true
},
“add-field”:{
“name”:”Provider_Id”,
“type”:”plong”,
“docValues”:true,
“indexed”:true,
“stored”:true
},
“add-field”:{
“name”:”Provider_Name”,
“type”:”text_general”,
“indexed”:true,
“stored”:true
},
“add-field”:{
“name”:”Provider_Street_Address”,
“type”:”string”,
“indexed”:false,
“stored”:true
},
“add-field”:{
“name”:”Provider_City”,
“type”:”string”,
“indexed”:true,
“stored”:true
},
“add-field”:{
“name”:”Provider_State”,
“type”:”string”,
“indexed”:true,
“stored”:true
},
“add-field”:{
“name”:”Provider_Zip_Code”,
“type”:”string”,
“indexed”:true,
“stored”:true
},
“add-field”:{
“name”:”Hospital_Referral_Region_Description”,
“type”:”text_general”,
“indexed”:true,
“stored”:true
},
“add-field”:{
“name”:”Total_Discharges”,
“type”:”pint”,
“docValues”:true,
“indexed”:true,
“stored”:true
},
“add-field”:{
“name”:”Average_Covered_Charges”,
“type”:”pdouble”,
“docValues”:true,
“indexed”:true,
“stored”:true
},
“add-field”:{
“name”:”Average_Total_Payments”,
“type”:”pdouble”,
“docValues”:true,
“indexed”:true,
“stored”:true
},
“add-field”:{
“name”:”Average_Medicare_Payments”,
“type”:”pdouble”,
“docValues”:true,
“indexed”:true,
“stored”:true
}
}' http://localhost:8983/solr/ipps/schemaThese are field names, field types, and whether or not to index and store the field. You can find out more about Solr’s data types and overall schema in the reference guide.
Now that we’ve got a schema we can “post” the data into Solr. There are many routes to do this. You could use curl or Postman, but Solr includes a command line tool, bin/post, which will be available out of the box on Linux and MacOS.
bin/post -c ipps -params "rowid=id" -type "text/csv" /home/acoliver/Downloads/Inpatient_Prospective_Payment_System__IPPS__Provider_Summary_for_the_Top_100_Diagnosis-Related_Groups__DRG__-_FY2011.csv
On Windows:
java -Dtype=text/csv -Dc=ipps -Dparams="rowid=id" -jar example\exampledocs\post.jar \Users\acoliver\Downloads\Inpatient_Prospective_Payment_System__IPPS__Provider_Summary_for_the_Top_100_Diagnosis-Related_Groups__DRG__-_FY2011.csv
W00t you have data!
Querying your data
There are language bindings for Solr that you can use for Java or Python, or if you’re more of a power developer you can use the one for PHP. Or you could just use curl or Postman or your browser.
Paste this into an address bar:
http://localhost:8983/solr/ipps/select?indent=on&q=*:*&wt=json
This URL is a simple query that returns the 10 most relevant results. You can change the pagination and find out more about Solr’s Solr’s query language and even alternative query parsers in the reference guide. If you want to see the same thing in XML you can configure that.
Maybe you want to do something a bit more advanced. Below finds procedures in the town I live in:
http://localhost:8983/solr/ipps/select?indent=on&q=Provider_State:NC%20AND%20Hospital_Referral_Region_Description:%22*Durham%22&wt=json
You can go much further and do more summaries and calculations and fuzzy matches.
Solr administration
Some of you are like “Good gosh, the command line scares me!” So that’s fine, Solr has a GUI. Got to http://localhost:8983/solr and see this beauty:
 IDG
IDGIf you select your collection on the side, you can even go to a screen that will let you fill in query parameters:
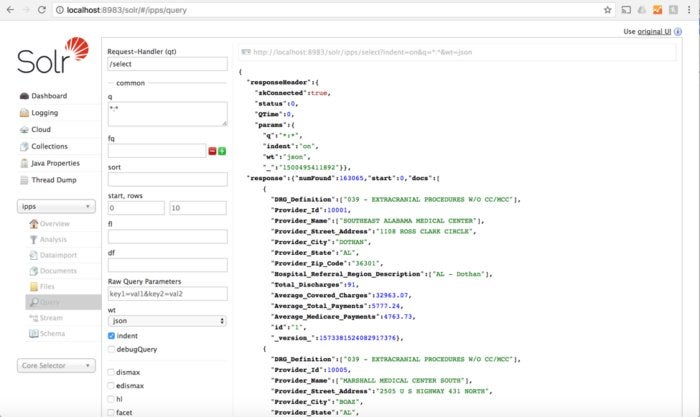 IDG
IDGIf that screen gives you a headache, you can just go to http://localhost:8983/solr/ipps/browse.
We’ve done simple text queries. You can also do ranges and spatial searches. If the “relevance” sorting isn’t working for you, you can do more advanced expressions and have Solr return things “as they are found” much like an RDBMS does it. You can sort on various fields and filter by categories. You can even have it “learn to rank”—a machine learning capability that lets Solr “learn” what users think is the most relevant result. We’ve really only scratched the surface.
Why Solr?
So clearly you might choose to use Solr if you need a search engine. However, it is also a redundant, distributed document database that offers SQL (out of the box) for those who want to connect tools like Tableau. It is extensible in Java (and other JVM languages), and yet with the REST-like interface you can easily speak JSON or XML to it.
Solr might not be your best choice if you have simple data that you’re looking up by key and doing mostly writes on. Solr has too much plumbing for doing bigger things to be as efficient for that as a key-value store.
Solr is a clear choice if your search is very text-centric. However, there are other not-so-obvious cases where it might be a good choice like for spatial searches on all those people whose cell phones you’ve hacked to track their location. I’m just saying that you, Mr. Putin, might want to choose Solr too.
Regardless, just remember that friends don’t let friends do SQL bla like '%stuff' queries.