






Apache Solr is an open source search engine at heart, but it is much more than that. It is a NoSQL database with transactional support. It is a document database that offers SQL support and executes it in a distributed manner.
Previously, I’ve shown you how to create and load a collection into Solr; you can load that collection now if you hadn’t done it previously. (Full disclosure: I work for Lucidworks, which employs many of the key contributors to the Solr project.)
In this post, I’ll show you more 10 more things you can do with that collection:
1. Filter queries
Consider this query:
http://localhost:8983/solr/ipps/select?fq=Provider_State:NC&indent=on&q=*:*&wt=json
On its face, this query looks similar to if I just did q=Provider_State:NC. However, filter queries return only IDs, and they don't affect the score. Filter queries are also cached. This is a good way to find the most relevant q=blue suede in department:footwear as opposed to department:clothing or department:music.
 IDG
IDG2. Faceting
Try this query:
http://localhost:8983/solr/ipps/select?facet=on&facet.field=Provider_State&facet.limit=-1&indent=on&q=*:*&wt=json
The following is returned at the top:
 ID
IDFaceting gives you your category counts (among other things). If you're implementing a retail site, this is how you provide categories and category counts for departments or other ways that you divide your inventory.
3. Range faceting
Add this to a query string: facet.interval=Average_Total_Payments&facet.interval.set=[0,1999.99]&facet.interval.set=[2000,2999.99]&facet.interval.set=[3000,3999.99]&facet.interval.set=[4000,4999.99]&facet.interval.set=[5000,5999.99]&facet.interval.set=[6000,6999.99]&facet.interval.set=[7000,7999.99]&&facet.interval.set=[8000,8999.99]&facet.interval.set=[9000,10000]
You'll get:
 IDG
IDGThis range faceting can help divide up a numeric field into categories of ranges. If you're helping someone find a laptop in the $2,000-$3,000 range, this is for you. You can do a similar query without hard-coding the ranges by doing this instead: facet.range=Average_Total_Payments&facet.range.gap=999.99&facet.range.start=2000&facet.range.end=10000
4. DocValues
In your schema, make sure the docValues attribute is selected for fields that you are faceting on. This optimizes the field for these sorts of searches and saves on memory at query time, as shown in this schema.xml excerpt:
<field name="manu_exact" type="string" indexed="false" stored="false" docValues="true" />
5. PseudoFields
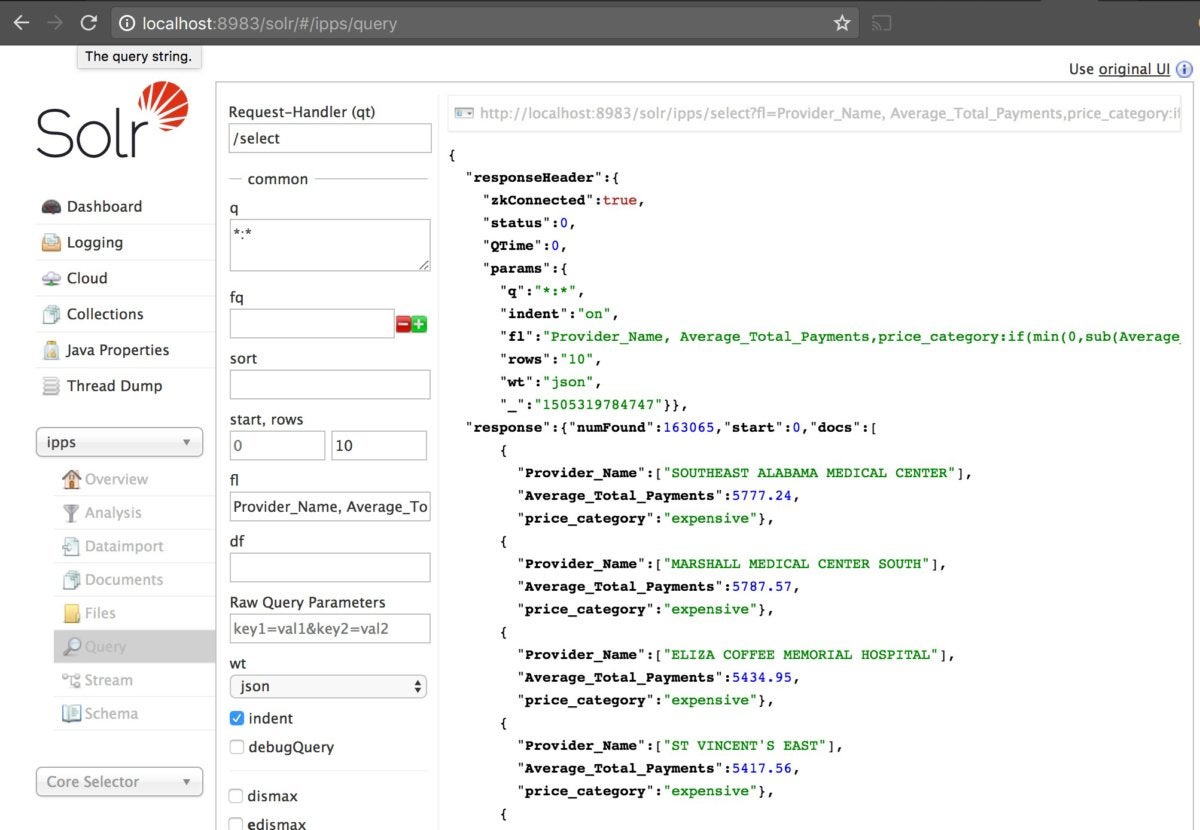
You can do operations on your data and return a value. Try this:
http://localhost:8983/solr/ipps/select?fl=Provider_Name,%20Average_Total_Payments,price_category:if(min(0,sub(Average_Total_Payments,5000)),%22inexpensive%22,%22expensive%22)&indent=on&q=*:*&rows=10&wt=json
 IDG
IDGThe example uses some of Solr's built-in functions to categorize providers as expensive or inexpensive based on the average total payments. I put price_category:if(min(0,sub(Average_Total_Payments,5000)),"inexpensive","expensive") in the fl, or field list, along with two other fields.
6. Query parsers
defType lets you pick one of Solr's query parsers. The default Standard Query Parser is really good for specific machine-generated queries. But Solr also has the Dismax and eDismax parsers, which are a better for normal people: You can click one of them at the bottom of the admin query screen or add defType=dismax to your query string. The Dismax parser generally produces better results for user-entered queries by finding the "disjunction maximum," or the field with the most matches, and adding it to the score.
7. Boosting
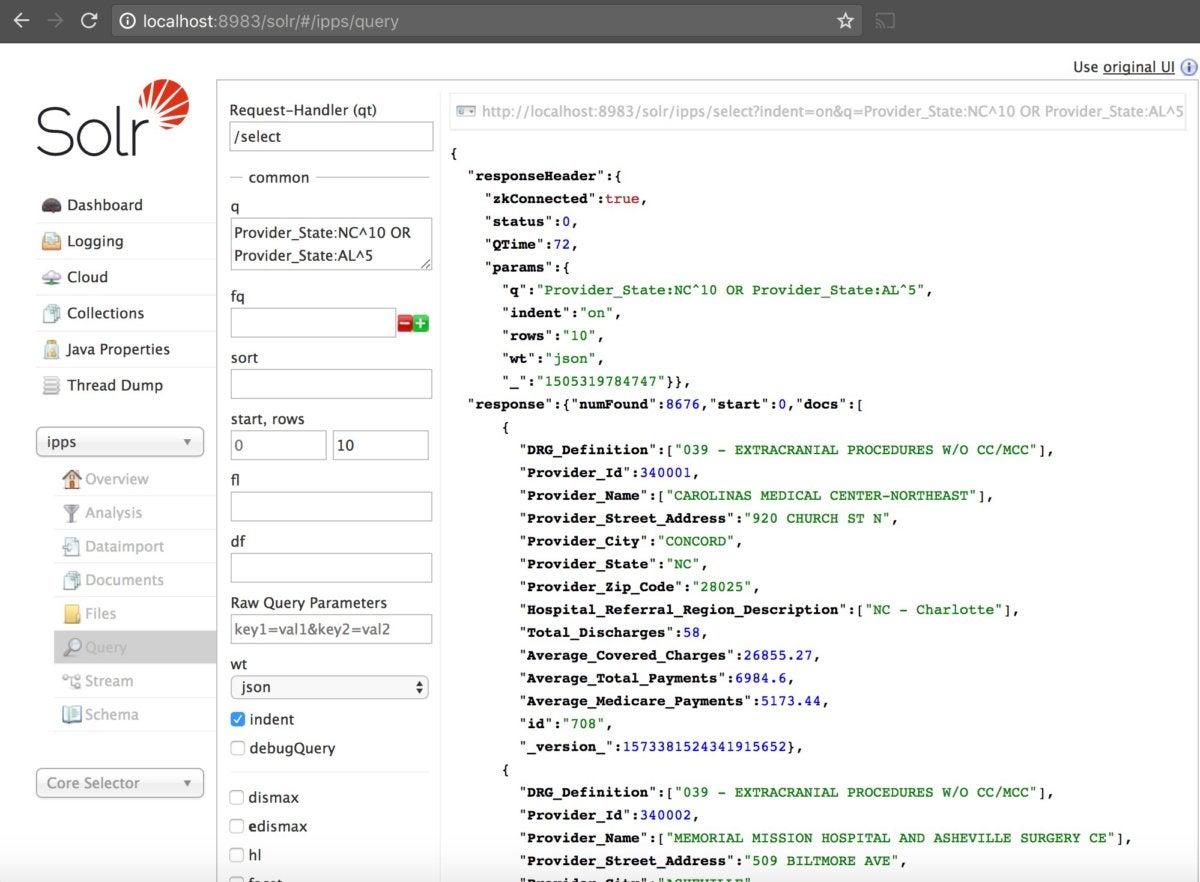
If you search Provider_State:AL^5 OR Provider_State:NC^10, results in North Carolina will be scored higher than results in Alabama. You can do this in your query (q=""). This is an important way to manipulate the results returned.
 IDG
IDG8. Date ranges
Although the example data doesn’t support any date-range searches, if it did it would be formatted like timestamp_dt:[2016-12-31T17:51:44.000Z TO 2017-02-20T18:06:44.000Z]. Solr supports date type fields and date type searches and filtering.
9. TF-IDF and BM25
The original scoring mechanism that Solr used (to determine which documents were relevant to your search term) is called TF-IDF, for “term frequency versus the inverse document frequency.” It returns how frequently a term occurs in your field or document versus how frequently that term occurs overall in your collection. The problem with this algorithm is that having "Game of Thrones" occur 100 times in a 10-page document versus ten times in a 10-page document doesn't make the document 10 times more relevant. It makes it more relevant but not 10 times more relevant.
BM25 smoothes this process, effectively letting documents reach a saturation point, after which the impact of additional occurrences are mitigated. Recent versions of Solr all use BM25 by default.
10. debugQuery
In the Admin Query console, you can check debugQuery to add debugQuery=on to the Solr query string. If you inspect the results, you'll find this output:
 IDG
IDGAmong other things you see it is using the LuceneQParser (the name of the standard query parser) and, above that, how each result was scored. You see the BM25 algorithm itself and how boosts affected the scoring. If you're trying to debug your search, this is a very valuable tool!
These ten aspects of Solr certainly help me when using Solr for search and tuning my results.