






Metering is not just a simple counting problem. Metering is often confused with measuring, but it is usually more than that. Metering does involve measuring, but as an ongoing process, usually with the goal of regulating the usage or flow of a resource over time. Modern applications incorporate metering in many different ways, ranging from counting people, objects, or events to regulating usage, controlling access, and allocating capacity.
Metering solutions generally must process large volumes of data while meeting stringent performance requirements. Depending on the scale of the solution, counting and metering might involve thousands if not millions of updates to a database every second. The primary requirements of a database to support such a solution are high throughput for write operations and low (sub-millisecond) latency for responses.
Redis, the open source in-memory database platform, delivers both of these benefits while also being cost-effective in terms of using minimal hardware resources. In this article we’ll examine certain features of Redis that make it a good choice for metering solutions, and how we can use Redis for that purpose. But first, let’s look at a few of the more common uses of metering.
Common metering applications
Metering is required in any application that must measure the use of a resource over time. Here are four common scenarios:
- Consumption-based pricing models. Unlike one-time or subscription-based payment models, consumption-based pricing models allow consumers to pay only for actual usage. Consumers enjoy greater flexibility, freedom, and cost savings while providers gain greater consumer retention.
Implementing such models can be tricky. Sometimes the metering system has to track many items of usage and many metrics in a single plan. For example, a cloud provider may set different pricing levels for CPU cycles, storage, throughput, number of nodes, or length of time a service is used. A telecommunications company may set different levels of allowed consumption for minutes, data, or text. The metering solution must enforce capping, charging, or extending services depending on the type of consumption-based pricing. - Restricting resource utilization. Every service on the Internet can be abused through excessive usage unless that service is rate limited. Popular services such as Google AdWords API and Twitter Stream API incorporate rate limits for this reason. Some extreme cases of abuse lead to denial of service (DoS). To prevent abuse, services and solutions that are accessible on the Internet must be designed with proper rate limiting rules. Even simple authentication and login pages must limit the number of retries for a given interval of time.
Another example where restricting resource utilization becomes necessary is when changing business requirements put a greater load on legacy systems than they can support. Rate limiting the calls to the legacy systems allows businesses to adapt to growing demand without needing to replace their legacy systems.
In addition to preventing abuse and reducing load, good rate limiting also helps with the management of bursty traffic scenarios. For example, an API enforcing a brute force rate-limiting method may allow 1000 calls every hour. Without a traffic-shaping policy in place, a client may call the API 1000 times in the first few seconds of every hour, perhaps exceeding what the infrastructure can support. Popular rate-limiting algorithms such as Token Bucket and Leaky Bucket prevent bursts by not only limiting the calls, but also distributing them over time. - Resource distribution. Congestion and delays are common scenarios in applications that deal with packet routing, job management, traffic congestion, crowd control, social media messaging, data gathering, and so on. Queueing models offer several options for managing the queue size based on the rate of arrival and departure, but implementing these models at large scale isn’t easy.
Backlog and congestion are constant worries when dealing with fast data streams. Clever designers need to define acceptable queue length limits, while incorporating both the monitoring of queuing performance and dynamic routing based on queue sizes. - Counting at scale for real-time decision making. E-commerce sites, gaming applications, social media, and mobile apps attract millions of daily users. Because more eyeballs yield greater revenue, counting visitors and their actions accurately is critical to business. Counting is similarly useful for use cases such as error retries, issue escalation, DDoS attack prevention, traffic profiling, on-demand resource allocation, and fraud mitigation.
Metering design challenges
Solution architects have to consider many parameters when building a metering application, starting with these four:
- Design complexity. Counting, tracking, and regulating volumes of data—especially when they arrive at a high velocity—is a daunting task. Solution architects can handle metering at the application layer by using programming language structures. However, such a design is not resilient to failures or data loss. Traditional disk-based databases are robust, and promise a high degree of data durability during failures. But not only do they fall short of providing the requisite performance, they also increase complexity without the right data structures and tools to implement metering.
- Latency. Metering typically involves numerous, constant updates to counts. Network and disk read/write latency adds up while dealing with large numbers. This could snowball into building up a huge backlog of data leading to more delays. The other source of latency is a program design that loads the metering data from a database to the program’s main memory, and writes back to the database when done updating the counter.
- Concurrency and consistency. Architecting a solution to count millions and billions of items can get complex when events are captured in different regions, and they all need to converge in one place. Data consistency becomes an issue if many processes or threads are updating the same count concurrently. Locking techniques avoid consistency problems and deliver transactional level consistency, but slow down the solution.
- Durability. Metering affects revenue numbers, which implies that ephemeral databases are not ideal in terms of durability. An in-memory datastore with durability options is a perfect choice.
Using Redis for metering applications
In the following sections we will examine how to use Redis for counting and metering solutions. Redis has built-in data structures, atomic commands, and time-to-live (TTL) capabilities that can be used to power metering use cases. Redis runs on a single thread. Therefore, all of the database updates are serialized, enabling Redis to perform as a lock-free data store. This simplifies the application design as developers don’t need to spend any effort on synchronizing the threads or implementing locking mechanisms for data consistency.
Atomic Redis commands for counting
Redis provides commands to increment values without the requirement of reading them to the application’s main memory.
Redis stores integers as a base-10 64-bit signed integer. Therefore the maximum limit for an integer is a very large number: 263 – 1 = 9,223,372,036,854,775,807.
Built-in time-to-live (TTL) on Redis keys
One of the common use cases in metering is to track usage against time and to limit resources after the time runs out. In Redis, one can set a time-to-live value for the keys. Redis will automatically disable the keys after a set timeout. The following table lists several methods of expiring keys.
The messages below give you the time-to-live on the keys in terms of seconds and milliseconds.
Redis data structures and commands for efficient counting
Redis is loved for its data structures such as Lists, Sets, Sorted Sets, Hashes, and Hyperloglogs. Many more can be added through the Redis modules API.
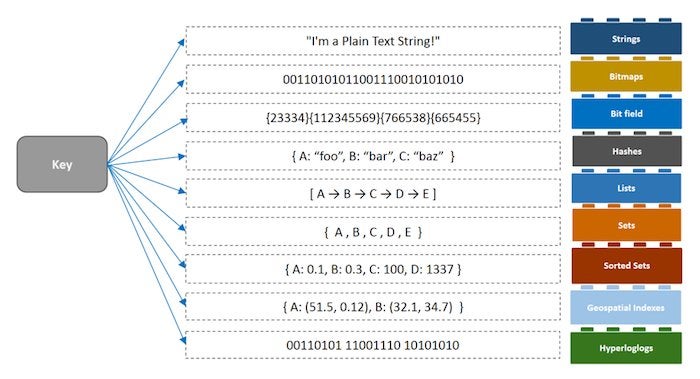 Redis Labs
Redis Labs
Redis data structures.
Redis data structures come with built-in commands that are optimized to execute with maximum efficiency in memory (right where the data is stored). Some data structures help you accomplish much more than the counting of objects. For example, the Set data structure guarantees uniqueness to all the elements.
Sorted Set goes a step further by ensuring that only unique elements are added to the set, and allowing you to order the elements based on a score. Ordering your elements by time in a Sorted Set data structure, for example, will offer you a time-series database. With the help of Redis commands you could get your elements in a certain order, or delete items that you don’t need anymore.
Hyperloglog is another special data structure that estimates counts of millions of unique items without needing to store the objects themselves or impact memory.
Redis persistence and in-memory replication
Metering use cases such as payments involve storing and updating information that is critical to businesses. Loss of data has a direct impact on revenue. It can also destroy billing records, which are often a compliance or governance requirement.
You can tune consistency and durability in Redis based on your data requirements. If you need a permanent proof of record for your metering data, you can achieve durability through Redis’s persistence capabilities. Redis supports AOF (append-only file), which copies write commands to disk as they happen, and snapshotting, which takes the data as it exists at one moment in time and writes it to disk.
Built-in lock-free Redis architecture
Redis processing is single threaded; this ensures data integrity, as all the write commands are automatically serialized. This architecture relieves the developers and architects from the burden of synchronizing threads in a multithreaded environment.
In the case of a popular consumer mobile application, thousands and sometimes millions of users might be accessing the application simultaneously. Let’s say the application is metering the time used, and two or more users can share minutes concurrently. The parallel threads can update the same object without imposing the additional burden of ensuring data integrity. This reduces the complexity of the application design while ensuring speed and efficiency.
Redis metering sample implementations
Let’s take a look at sample code. Several of the scenarios below would require very complex implementations if the database used was not Redis.
Blocking multiple login attempts
To prevent unauthorized access to accounts, websites sometimes block users from making multiple login attempts within a stipulated time period. In this example, we restrict the users from making more than three login attempts in an hour using simple key time-to-live functionality.
The key to hold the number of login attempts:
user_login_attempts:<user id>
Steps:
Get the current number of attempts:
GET user_login_attempts:<user id>
If null, then set the key with the expiration time in seconds (1 hour = 3600 seconds):
SET user_login_attempts:<user id> 1 3600
If not null and if the count is greater than 3, then throw an error:
If not null, and if the count is less than or equal to 3, increment the count:
INCR user_login_attempts:<user id>
Upon a successful login attempt, the key may be deleted as follows:
DEL user_login_attempts:<user id>
Pay as you go
The Redis Hash data structure provides easy commands to track usage and billing. In this example, let’s assume every customer has their billing data stored in a Hash, as shown below:
customer_billing:<user id>
usage<actual usage in the unit which the billing is based upon>
cost<cost billed to the customer>
.
.
Suppose each unit costs two cents, and the user consumed 20 units. The commands to update the usage and billing are:
hincrby customer:<user id> usage 20
hincrbyfloat customer:<user id> cost .40
As you may have noticed, your application can update the information in the database without requiring it to load the data from the database into its own memory. Additionally, you could modify an individual field of a Hash object without reading the whole object.
Please note: The purpose of this example is to show how to use the hincrby and hincrbyfloat commands. In a good design, you avoid storing redundant information such as both usage and cost.