






The development landscape is ripe with new languages and improvements on existing ones. Mozilla’s Rust, Apple’s Swift, Kotlin from JetBrains, and the experimental Python variant Mojo (and many others) offer developers a wide range of choices for speed, safety, convenience, portability, and power.
The arrival of new tools for building languages—specifically, compilers—is a big factor in this abundance. And chief among compilers is LLVM, an open source project originally developed by Swift language creator Chris Lattner at the University of Illinois.
LLVM makes it easier to not only create new languages but enhance the development of existing ones. It provides tools for automating many of the most thankless parts of creating a new language: developing a compiler, porting the outputted code to multiple platforms and architectures, generating architecture-specific optimizations such as vectorization, and writing code to handle common language metaphors like exceptions. Its liberal licensing means LLVM can be freely reused as a software component or deployed as a service.
The roster of languages using LLVM includes many familiar names. Apple’s Swift language uses LLVM as its compiler framework, and Rust uses it as a core component of the Rust toolchain. Many compilers use LLVM including Clang, the C/C++ compiler (hence the name, “C-lang”). Mono, the .NET implementation, has an option to compile to native code using an LLVM back end. And Kotlin, nominally a JVM language, offers a compiler technology called Kotlin/Native that uses LLVM to compile to machine-native code.
What is LLVM?
At heart, LLVM is a library for programmatically creating machine-native code. A developer uses the API to generate instructions in a format called an intermediate representation, or IR. LLVM can then compile the IR into a standalone binary or perform a JIT (just-in-time) compilation on the code to run in the context of another program, such as an interpreter or runtime for the language.
LLVM’s APIs provide primitives for developing many common structures and patterns found in programming languages. For example, almost every language has the concept of a function and of a global variable, and many have coroutines and C foreign-function interfaces. LLVM has functions and global variables as standard elements in its IR, and it has metaphors for creating coroutines and interfacing with C libraries.
Instead of spending your time reinventing those wheels, you can just use LLVM’s implementations and focus on the parts of your language that need more attention.
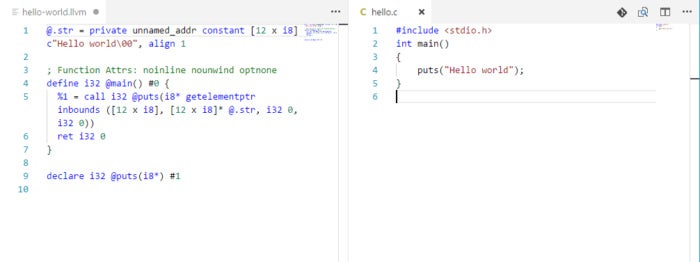 IDG
IDG
An example of LLVM’s intermediate representation (IR). On the right is a simple program in C; on the left is the same code translated into LLVM IR by the Clang compiler.
LLVM is designed for portability
To understand LLVM, it might help to consider an analogy to the C programming language: C is sometimes described as a portable, high-level assembly language. This is because C has constructions that can map closely to system hardware, and it has been ported to almost every system architecture. But C is useful as a portable assembly language only up to a point; it wasn’t designed for that particular purpose.
By contrast, LLVM’s IR was designed from the beginning to be a portable assembly. One way it accomplishes this portability is by offering primitives independent of any particular machine architecture. For example, integer types aren’t confined to the maximum bit width of the underlying hardware (such as 32 or 64 bits). You can create primitive integer types using as many bits as needed, like a 128-bit integer. You also don’t have to worry about crafting output to match a specific processor’s instruction set; LLVM takes care of that for you.
LLVM’s architecture-neutral design makes it easier to support hardware of all kinds, present and future. For instance, IBM contributed code to support its z/OS, Linux on Power (including support for IBM's MASS vectorization library), and AIX architectures for LLVM’s C, C++, and Fortran projects.
If you want to see live examples of LLVM IR, you can go to the Godbolt Compiler Explorer site, and translate C or C++ into LLVM IR. Select Clang as the compiler, then, from Add new, select LLVM IR to open a tab that shows LLVM IR code generated from supplied C/C++ code.
How programming languages uses LLVM
The most common use case for LLVM is as an ahead-of-time (AOT) language compiler. For example, the Clang project ahead-of-time compiles C and C++ to native binaries. But LLVM makes other things possible, as well.
Just-in-time compiling with LLVM
Some situations require generating code on the fly at runtime, rather than compiling it ahead of time. The Julia language, for example, JIT-compiles its code, because it needs to run fast and interact with the user via a REPL (read-eval-print loop) or interactive prompt.
Numba, a math-acceleration package for Python, JIT-compiles selected Python functions to machine code. It can also compile Numba-decorated code ahead of time, but (like Julia) Python offers rapid development by being an interpreted language. Using JIT compilation to produce such code complements Python’s interactive workflow better than ahead-of-time compilation.
Others are experimenting with new ways to use LLVM as a JIT compiler, such as compiling PostgreSQL queries, yielding up to a fivefold increase in performance.
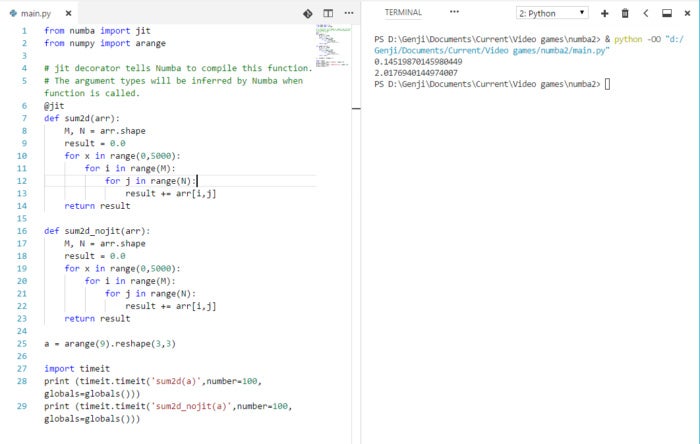 IDG
IDG
Numba uses LLVM to just-in-time-compile numerical code and accelerate its execution. The JIT-accelerated sum2d function completes an execution about 139 times faster than the regular Python code.
Automatic code optimization with LLVM
LLVM doesn’t just compile the IR to native machine code. You can also programmatically direct it to optimize the code with a high degree of granularity, all the way through the linking process. The optimizations can be quite aggressive, including things like inlining functions, eliminating dead code (including unused type declarations and function arguments), and unrolling loops.
Again, the power is in not having to implement all this yourself. LLVM can handle those tasks for you, or you can direct it to toggle them off and on as needed. For example, if you want smaller binaries at the cost of some performance, you could have your compiler front end tell LLVM to disable loop unrolling.
Domain-specific languages with LLVM
LLVM has been used to produce compilers for many general-purpose languages, but it’s also useful for producing languages that are highly vertical or exclusive to a problem domain. In some ways, this is where LLVM shines brightest, because it removes a lot of the drudgery in creating such a language and makes it perform well.
The Emscripten project, for example, takes LLVM IR code and converts it into JavaScript, in theory allowing any language with an LLVM back end to export code that can run in-browser. One of the long-term results of this work is LLVM-based back ends that can produce WebAssembly, allowing languages like Rust to compile directly to WASM as a target.
Another way LLVM can be used is to add domain-specific extensions to an existing language. Nvidia used LLVM to create the Nvidia CUDA Compiler, which lets languages add native support for CUDA that compiles as part of the native code you’re generating (faster), instead of being invoked through a library shipped with it (slower).
LLVM’s success with domain-specific languages has spurred new projects within LLVM to address the problems they create. The biggest issue is how some DSLs are hard to translate into LLVM IR without a lot of hard work on the front end. One solution in the works is the Multi-Level Intermediate Representation, or MLIR project.
MLIR provides convenient ways to represent complex data structures and operations, which can then be translated automatically into LLVM IR. For example, the TensorFlow machine learning framework could have many of its complex dataflow-graph operations efficiently compiled to native code with MLIR.
How to work with LLVM
The typical way to work with LLVM is via code in a language that supports LLVM’s libraries.
Two common language choices are C and C++. Many LLVM developers default to one of those two for good reasons:
- LLVM itself is written in C++.
- LLVM’s APIs are available in C and C++ incarnations.
- Much language development tends to happen with C/C++ as a base.
Still, those two languages are not the only choices. Many languages can call natively into C libraries, so it’s theoretically possible to perform LLVM development with any such language. But it helps to have an actual library in the language that elegantly wraps LLVM’s APIs. Fortunately, many languages and language runtimes have such libraries, including C#/.NET/Mono, Rust, Haskell, OCAML, Node.js, Go, and Python.
One caveat is that some of the language bindings to LLVM may be less complete than others. With Python, for example, many choices cropped up over time, varying in completeness and utility, with a top contender emerging.
- llvmlite, developed by the team that creates Numba, has emerged as the current contender for working with LLVM in Python. It implements only a subset of LLVM’s functionality, as dictated by the needs of the Numba project. But that subset provides the vast majority of what LLVM users need. To that end,
llvmliteis generally the best choice for working with LLVM in Python. - The LLVM project has its own set of bindings to LLVM’s C API, but they are currently not maintained.
- llvmpy, the first popular Python binding for LLVM, fell out of maintenance in 2015. That's bad for any software project, but worse when working with LLVM, given the number of changes that come along in each new edition.
- llvmcpy aims to bring the Python bindings for the C library up to date, keep them updated in an automated way, and make them accessible using Python’s native idioms.
llvmcpycan currently do some rudimentary work with the LLVM APIs, but it has not been updated since 2019.
If you’re curious about how to use LLVM libraries to build a language, LLVM’s creators have a tutorial, using either C++ or OCAML, that steps you through creating a simple language called Kaleidoscope. It’s since been ported to other languages:
- Haskell: A direct port of the original tutorial.
- Python: One such port follows the tutorial closely, while the other is a more ambitious rewrite with an interactive command line. Both of those use
llvmliteas the bindings to LLVM. - Rust and Swift: It seemed inevitable we’d get ports of the tutorial to two of the languages that LLVM helped bring into existence.
Finally, the LLVM tutorial is also available in human languages. It has been translated into Chinese, using the original C++ and Python.
What LLVM doesn’t do
With all that LLVM does provide, it’s useful to also know what it doesn’t do.
For instance, LLVM does not parse a language’s grammar. Many tools already do that job, like lex/yacc, flex/bison, Lark, and ANTLR. Parsing is meant to be decoupled from compilation anyway, so it’s not surprising LLVM doesn’t try to address any of this.
LLVM also does not directly address the larger culture of software around a given language. Installing the compiler’s binaries, managing packages in an installation, and upgrading the toolchain—you'll need to do all that on your own.
Finally, and most important, there are still common parts of languages that LLVM doesn’t provide primitives for. Many languages have some manner of garbage-collected memory management, either as the main way to manage memory or as an adjunct to strategies like RAII (which C++ and Rust use). LLVM doesn’t give you a garbage-collector mechanism, but it does provide tools to implement garbage collection by allowing code to be marked with metadata that makes writing garbage collectors easier.
None of this rules out the possibility that LLVM might eventually add native mechanisms for implementing garbage collection. LLVM is developing quickly, with a major release every six months or so. And the pace of development is likely to only pick up thanks to the way many current languages have put LLVM at the heart of their development process.