






Bending the consistency and availability as described by the CAP theorem has been a great challenge for the architects of geo-distributed applications. Network partition is unavoidable. The high latency between data centers always results in some disconnect between the data centers for a short period of time. Thus traditional architectures for geo-distributed applications are designed to either give up data consistency or take a hit on availability.
Unfortunately, you cannot afford to sacrifice availability for interactive user applications. In recent times, the architects have taken a shot at consistency and embraced the eventual consistency model. In this model, the applications depend on the database management system to merge all the local copies of the data to make them eventually consistent.
Everything looks good with the eventual consistency model until there are data conflicts. A few eventual consistency models promise best effort to fix the conflicts, but fall short of guaranteeing strong consistency. The good news is, the models built around conflict-free replicated data types (CRDTs) deliver strong eventual consistency.
CRDTs achieve strong eventual consistency through a predetermined set of conflict resolution rules and semantics. Applications built on top of CRDT-based databases must be designed to accommodate the conflict resolution semantics. In this article we will explore how to design, develop, and test geo-distributed applications using a CRDT-based database. We will also examine four sample use cases: counters, distributed caching, shared sessions, and multi-region data ingest.
My employer, Redis Labs, recently announced CRDT support in Redis Enterprise, with conflict-free replicated data types joining the rich portfolio of data structures—Strings, Hashes, Lists, Sets, Sorted Sets, Bitfields, Geo, Hyperloglog, and Streams—in our database product. However, the following discussion applies not only to Redis Enterprise, but to all CRDT-based databases.
Databases for geo-distributed applications
For geo-distributed applications, it’s common to run services local to the clients. This reduces the network traffic and the latency caused by the roundtrip. In many cases, the architects design the services to connect to a local database. Then comes the question of how you maintain consistent data across all the databases. One option is to handle this at the application level—you can write a periodic job process that will synchronize all the databases. Or you could rely on a database that will synchronize the data between the databases.
For the rest of the article, we assume that you’ll go with the second option—let the database do the work. As shown in Figure 1 below, your geo-distributed application runs services in multiple regions, with each service connecting to a local database. The underlying database management system synchronizes the data between the databases deployed across the regions.
 Redis Labs
Redis Labs
Figure 1. Sample architecture of a geo-distributed application that uses an active-active database.
Data consistency models
A consistency model is a contract between the distributed database and the application that defines how clean the data is between write and read operations.
For example, in a strong consistency model, the database guarantees that the applications will always read the last write. With sequential consistency, the database assures that the order of data you read is consistent with the order in which it was written to the database. In the eventual consistency model, the distributed database promises to synchronize and consolidate the data between the database replicas behind the scenes. Therefore, if you write your data to one database replica and read it from another, it’s possible that you won’t read the latest copy of the data.
Strong consistency
The two-phase commit is a common technique to achieve strong consistency. Here, for every write operation (add, update, delete) at a local database node, the database node propagates the changes to all the database nodes and waits for all the nodes to acknowledge. The local node then sends a commit to all the nodes and waits for another acknowledgement. The application will be able to read the data only after the second commit. The distributed database will not be available for write operations when the network disconnects between the databases.
Eventual consistency
The main advantage of the eventual consistency model is that the database will be available to you to perform write operations even when the network connectivity between the distributed database replicas breaks down. In general, this model avoids the round-trip time incurred by a two-phase commit, and therefore supports far more write operations per second than the other models. One problem that eventual consistency must address is conflicts—simultaneous writes on the same item at two different locations. Based on how they avoid or resolve conflicts, the eventually consistent databases are further classified in the following categories:
- Last writer wins (LWW). In this strategy, the distributed databases rely on the timestamp synchronization between the servers. The databases exchange the timestamp of each write operation along with the data itself. Should there be a conflict, the write operation with the latest timestamp wins.
The disadvantage of this technique is that it assumes all the system clocks are synchronized. In practice, it’s difficult and expensive to synchronize all the system clocks. - Quorum-based eventual consistency: This technique is similar to the two-phase commit. However, the local database doesn’t wait for the acknowledgement from all the databases; it just waits for the acknowledgement from a majority of the databases. The acknowledgement from the majority establishes a quorum. Should there be a conflict, the write operation that has established the quorum wins.
On the flip side, this technique adds network latency to the write operations, which makes the app less scalable. Also, the local database will not be available for writes if it gets isolated from the other database replicas in the topology. - Merge replication: In this traditional approach, which is common among the relational databases, a centralized merge agent merges all the data. This method also offers some flexibility in implementing your own rules for resolving conflicts.
Merge replication is too slow to support real-time, engaging applications. It also has a single point of failure. As this method doesn’t support pre-set rules for conflict resolution, it often leads to buggy implementations for conflict resolution. - Conflict-free replicated data type (CRDT): You will learn about CRDTs in detail in the next few sections. In a nutshell, CRDT-based databases support data types and operations that deliver conflict-free eventual consistency. CRDT-based databases are available even when the distributed database replicas cannot exchange the data. They always deliver local latency to the read and write operations.
Limitations? Not all database use cases benefit from CRDTs. Also, the conflict resolution semantics for CRDT-based databases are predefined and cannot be overridden.
What are CRDTs?
CRDTs are special data types that converge data from all database replicas. The popular CRDTs are G-counters (grow-only counters), PN-counters (positive-negative counters), registers, G-sets (grow-only sets), 2P-sets (two-phase sets), OR-sets (observed-remove sets), etc. Behind the scenes, they rely on the following mathematical properties to converge the data:
- Commutative property: a ☆ b = b ☆ a
- Associative property: a ☆ ( b ☆ c ) = ( a ☆ b ) ☆ c
- Idempotence: a ☆ a = a
A G-counter is a perfect example of an operational CRDT that merges the operations. Here, a + b = b + a and a + (b + c) = (a + b) + c. The replicas exchange only the updates (additions) with each other. The CRDT will merge the updates by adding them up. A G-set, for example, applies idempotence ({a, b, c} U {c} = {a, b, c}) to merge all the elements. Idempotence avoids duplication of elements added to a data structure as they travel and converge via different paths.
CRDT data types and their conflict resolution semantics
Conflict-free data structures: G-counters, PN-counters, G-Sets
All of these data structures are conflict-free by design. The tables below show how the data is synchronized between the database replicas.
 Redis Labs
Redis Labs
Figure 2: An example to show how PN-counters synchronize updates.
 Redis Labs
Redis Labs
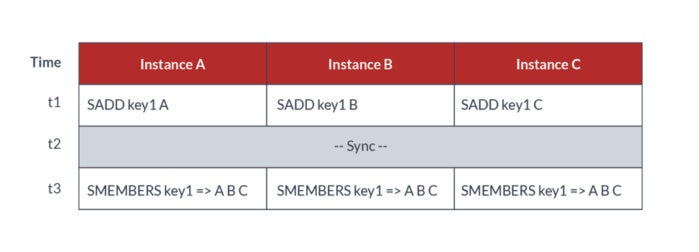
Figure 3: G-Sets guarantee unique elements.
G-counters and PN-counters are popular for use cases such as global polling, stream counts, activity tracking, and so on. G-sets are heavily used to implement blockchain technology. Bitcoins, for example, employ append-only blockchain entries.
Registers: Strings, Hashes
Registers are not conflict-free by nature. They typically follow the policies of LWW or quorum-based conflict resolution. Figure 4 shows an example of how a register resolves the conflict by following the LWW policy.
 Redis Labs
Redis Labs
Figure 4: LWW policy for registers.
Registers are mainly used to store caching and session data, user profile information, product catalog, etc.
2P-sets
Two-phase sets maintain two sets of G-sets—one for added items and the other for removed items. The replicas exchange the G-set additions when they synchronize. Conflict arises when the same element is found in both the sets. In some CRDT-based databases such as Redis Enterprise this is handled by the policy, “Add wins over the delete.”
 Redis Labs
Redis Labs
Figure 5: Add wins over delete for a 2P-set.
The 2P-set is a good data structure for storing shared session data such as shopping carts, a shared document, or a spreadsheet.
How to architect an application to use a CRDT-based database
Connecting your application to a CRDT-based database is no different from connecting your application to any other database. However, because of the eventual consistency policies, your application needs to follow a certain set of rules to deliver a consistent user experience. Three keys:
- Make your application stateless. A stateless application is typically API-driven. Every call to an API results in reconstructing the complete message from scratch. This ensures that you always pull a clean copy of data at any point of time. The low local latency offered by a CRDT-based database makes reconstructing messages faster and easier.
- Select the right CRDT that fits your use case. The counter is the simplest of the CRDTs. It can be applied for use cases such as global voting, tracking active sessions, metering, etc. However, if you want to merge the state of distributed objects, then you must consider other data structures, too. For example, for an application that allows users to edit a shared document, you may want to preserve not just the edits, but also the order in which they were performed. In that case, saving the edits in a CRDT-based list or a queue data structure would be a better solution than storing them in a register. It’s also important that you understand the conflict resolution semantics enforced by the CRDTs, and that your solution conforms to the rules.
- CRDT isn’t a one-size-fits-all solution. While CRDT is indeed a great tool for many use cases, it may not be the best for all use cases (ACID transactions, for example). CRDT-based databases generally fit well with microservices architecture where you have a dedicated database for each microservice.
The main takeaway here is that your application should focus on the logic and delegate the data management and synchronization complexity to the underlying database.
Testing applications with a distributed multi-master database
To achieve faster go-to-market, we recommend that you have a consistent development, testing, staging, and production setup. Among other things, that means your development and testing setup must have a miniaturized model of your distributed database. Check whether your CRDT-based database is available as a Docker container or a virtual appliance. Deploy your database replicas on different subnets so that you can simulate connected and disconnected cluster setup.
Testing applications with a distributed multi-master database may sound complex. But most of the time all you will be testing for is data consistency and application availability in two situations: When the distributed databases are connected, and when there is a network partition between the databases.
By setting up a three-node distributed database in your development environment, you can cover (and even automate) most of the testing scenarios in the unit testing. Here are the basic guidelines for testing your applications:
- Test cases when network connectivity is on and latency between the nodes is low: Your test cases must have more emphasis on simulating conflicts. Typically, you do this by updating the same data across different nodes many times. Incorporate steps to pause and verify the data across all nodes. Even though the database replicas synchronize continuously, testing the eventual consistency will necessitate pausing your test and checking the data. For validation, you will want to verify two things: That all of the database replicas have the same data, and that whenever a conflict occurred, the conflict resolution happened as per the design.
- Test cases for partitioned networks: Here you typically execute the same test cases as earlier, but in two steps. In the first step, you test the application with a partitioned network – i.e., a situation where the databases are unable to synchronize with each other. When the network is split, the database doesn’t merge all the data. Therefore, your test case must assume that you are reading only a local copy of the data. In the second step, you reconnect all the networks to test how the merge occurs. If you are following the same test cases as in the previous section, the eventual final data must be the same as in the previous set of steps.
How to use CRDTs in your applications
In this section we demonstrate how you can use CRDTs in your applications. Here we cover four sample implementations for CRDTs: counters, distributed caching, collaboration using shared session data, and multi-region data ingest.
CRDT use case: Counters (polling, likes, hearts, emoji counts)
Counters have many applications. You may have a geo-distributed application that is collecting the votes, measuring the number of “likes” on an article, or tracking the number of emoji reactions to a message. In this example, the application local to each geographical location connects to the nearest database cluster. It updates the counter and reads the counter with local latencies.
 Redis Labs
Redis Labs
Figure 6. Sample illustration of a counter data type.
Data type
PN-Counter
Pseudocode
// 1. Counter shared across all users
void countVote(String pollId){
// CRDT Command: COUNTER_INCREMENT poll:[pollId]:counter
}
// 2. Read the global count
long getVoteCount(String pollId){
// CRDT Command: COUNTER_GET poll:[pollId]:counter
}
Test cases for connected network
Increment count at one region
- Run your app in all regions; increment the counter at one location
- Stop the counter
- Your app at all regions reflects the latest counter value
Increment count at multiple regions
- Run your app in all regions; increment the counter at all locations
- Stop the counter; note the individual counts by region
- Your app must be consistent across all regions, with all regions showing the same count
Test cases for partitioned network
Increment count at multiple regions
- Isolate CRDT database replicas
- Run your app in all regions; increment the counter at all locations
- Stop the counter; note the individual counts by region
- Your app shows only the local increments
- Reconnect the networks
- All locations show the updated count; your app adjusts to this behavior
CRDT use case: Distributed caching
The caching mechanism for a distributed cache is the same as the one used in local caching: Your application tries to fetch an object from the cache. If the object doesn’t exist, the app retrieves from the primary store and saves it in the cache with an appropriate expiration time. If you store your cached object in a CRDT-based database, the database automatically makes the cache available across all the regions. In this example, the poster image for each movie cached locally gets distributed to all the locations.
 Redis Labs
Redis Labs
Figure 7. Step 1: The poster image is stored in the cache locally.
 Redis Labs
Redis Labs
Figure 8. Step 2: The CRDT-based database synchronizes the cache across all the regions.
Data type
Register. Verify the conflict resolution semantic implemented by your CRDT-based database. If your database supports time-to-live (TTL) on the objects, ensure your objects are expired across all the replicas.
Pseudocode
// 1. Cache an object as a string
void cacheString(String objectId, String cacheData, int ttl){
// CRDT command: REGISTER_SET object:[objectId] [cacheData] ex [ttl]
}
// 2. Get a cached item as a string
String getFromCache(String objectId){
// CRDT command: REGISTER_GET object:[objectId]
}
Test cases for connected network
Run your app in all regions; set a new cache object in all regions. Verify that your application can pull cached objects from the local clusters, even if the objects were cached at other locations.
Test cases for partitioned network
Simulate a network partition, set values, and reconnect. Verify that your application is designed to handle the following scenarios:
- Updating the same key results in last writer wins
- The keys upon merge get the longest value of TTL
CRDT use case: Collaboration using shared session data
CRDTs were initially developed to support multi-user document editing. Shared sessions are used in gaming, e-commerce, social networking, chat, collaboration, emergency responders, and many more applications. In this example, we demonstrate how you can develop a simple wedding registry application. In this application, all the well-wishers of a newly married couple add their gifts to a shopping cart that is managed as a shared session.
The registry application is a geo-distributed application with each instance connecting to the local database. To begin a session, the owners of the registry invite their friends from across the world. Once the invitees accept the invitation, they all get access to the session object. Later, they shop and add items to the shopping cart.
 Redis Labs
Redis Labs
Figure 9. Step 1: The couple invites their international friends to their wedding registry.
 Redis Labs
Redis Labs
Figure 10. Step 2: Invitees add their items to the shopping cart.
 Redis Labs
Redis Labs
Figure 11. Step 3: The owners of the wedding registry now have all the items that they can check out.
Data types
2P-Set and a PN-counter to hold the items of a shopping cart, plus a 2P-Set to store active sessions.
Pseudocode
void joinSession(String sharedSessionID, sessionID){
// CRDT command: SET_ADD sharedSession:[sharedSessionId] [sessionID]
}
void addToCart(String sharedSessionId, String productId, int count){
// CRDT command:
// ZSET_ADD sharedSession:[sharedSessionId] productId count
}
getCartItems(String sharedSessionId){
// CRDT command:
// ZSET_RANGE sharedSession:sessionSessionId 0 -1
}Test whether your app reflects the CRDT rules:
- Weights behave like a counter; adding the same object twice results in two objects in the sorted set
- Add wins over remove
Test cases for connected network
Run your app in all regions, add objects to the distributed Sorted Set data structure. Weights behave like a counter; adding the same object twice results in two objects in the Sorted Set. Verify whether your application conforms to these CRDT semantics.
Test cases for partitioned network
Simulate a network partition. Add and remove objects from the local cluster. Reconnect and verify whether your application is designed to handle the CRDT semantics of a Sorted Set.
CRDT use case: Multi-region data ingest
Lists or queues are used in many applications. In this example, we demonstrate how you can implement a distributed job order processing solution. As shown in Figure 12, the job order processing system maintains active jobs in a CRDT-based List data structure. The solution collects jobs at various locations. The distributed application at each location connects to the nearest database replica. This reduces the network latency for write operations, which in turn allows the application to support a high volume of job submissions. The jobs are popped out of the List data structure from one of the clusters. This assures that a job is processed only once.
 Redis Labs
Redis Labs
Figure 12. Sample illustration of multi-region data ingest.
Data types
CRDT-based list. The list data structure is used as a FIFO queue.
Pseudocode
pushJob(String jobQueueId, String job){
// CRDT command: LIST_LEFT_PUSH job:[jobQueueId] [job]
}
popJob(String jobQueueId){
// CRDT command: LIST_RIGHT_POP job:[jobQueueId]
}Test cases for connected network
Run your app in all regions, add objects to the List data structure. CRDT merges the objects added to the list. Verify whether your application conforms to the CRDT semantics of the List data structure.
Caution: If your application pops an object out of the list at one cluster, then your job processor is assured of processing one job. However, if you pop objects out of all the clusters, then two or more locations may end up processing the same job. If your application requires that you process a job only once, then you will need to implement your own locking solution at the application layer.
Test cases for partitioned network
Simulate a network partition. Add jobs to the local cluster. Reconnect and verify whether your application is designed to handle the CRDT semantics of a List.
CRDT-based databases enable you to build highly engaging geo-distributed applications. In this article, we covered four use cases that apply CRDTs: global counters, distributed caching, a shared session store, and multi-region data ingest. By leveraging a CRDT-based database in these and other scenarios, you can focus on your business logic and not worry about data synchronization between the regions. More than anything, CRDT-based databases deliver local latency for engaging applications, yet promise strong eventual consistency even when there is a network breakdown between data centers.
Roshan Kumar is a senior product manager at Redis Labs. He has extensive experience in software development and technology marketing. Roshan has worked at Hewlett-Packard and many successful Silicon Valley startups including ZillionTV, Salorix, Alopa, and ActiveVideo. As an enthusiastic programmer, he designed and developed mindzeal.com, an online platform hosting computer programming courses for young students. Roshan holds a bachelor’s degree in computer science and an MBA from Santa Clara University.
—
New Tech Forum provides a venue to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to newtechforum@infoworld.com.