






Redis, the in-memory multi-model database, is popular for many use cases. These include content caching, session stores, real-time analytics, message brokering, and data streaming. Last year I wrote about how to use Redis Pub/Sub, Lists, and Sorted Sets for real-time stream processing. Now, with the arrival of Redis 5.0, Redis has a brand-new data structure designed to managing streams.
With the Redis Streams data structure, you can do a lot more than what was possible with Pub/Sub, Lists, and Sorted Sets. Among the many benefits, Redis Streams enables you to do the following:
- Collect large volumes of data arriving in high velocity (the only bottleneck is your network I/O);
- Create a data channel between many producers and many consumers;
- Effectively manage your consumption of data even when producers and consumers don’t operate at the same rate;
- Persist data when your consumers are offline or disconnected;
- Communicate between producers and consumers asynchronously;
- Scale your number of consumers;
- Implement transaction-like data safety when consumers fail in the midst of consuming data; and
- Use your main memory efficiently.
The best part of Redis Streams is that it’s built into Redis, so there are no extra steps required to deploy or manage Redis Streams. In this article, I’ll walk you through the basics of using Redis Streams. We’ll look at how we can add data to a stream, and how we can read that data (all at once, asynchronously, as it arrives, etc.) to satisfy different consumer use cases.
In two future articles here, I will discuss how Redis Streams’ consumer groups work, and I will show a working application that uses Redis Streams.
Understand data flow in Redis Streams
Redis Streams provides an “append only” data structure that appears similar to logs. It offers commands that allow you to add sources to streams, consume streams, and monitor and manage how data is consumed. The Streams data structure is flexible, allowing you to connect producers and consumers in several ways.
 Redis Labs
Redis Labs
Figure 1. A simple application of Redis Streams with one producer and one consumer.
Figure 1 demonstrates the basic usage of Redis Streams. A single producer acts as a data source, and its consumer is a messaging application that sends data to the relevant recipients.
 Redis Labs
Redis Labs
Figure 2. An application with multiple consumers reading data from Redis Streams.
In Figure 2, a common data stream is consumed by more than one consumer. With Redis Streams, consumers can read and analyze the data at their own pace.
In the next application, shown in Figure 3, things get a bit more complex. This service receives data from multiple producers, and stores all of it in a Redis Streams data structure. The application has multiple consumers reading the data from Redis Streams, as well as a consumer group, which supports consumers that cannot operate at the same rate as the producers.
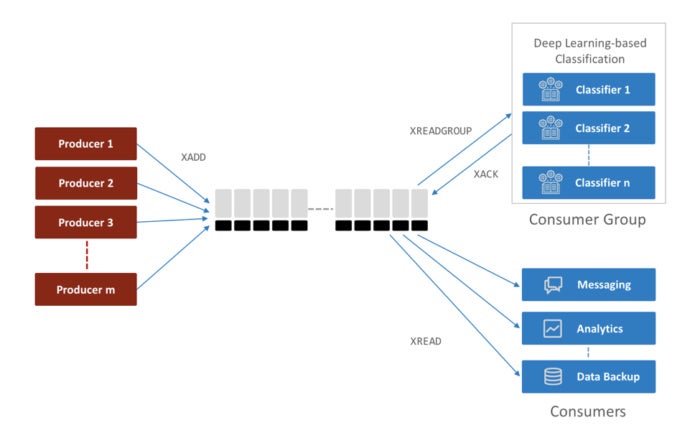 Redis Labs
Redis Labs
Figure 3. Redis Streams supporting multiple producers and consumers.
Add data to a stream with Redis Streams
The diagram in Figure 3 shows only one way to add data to a Redis Stream. Although one or more producers can add data to the data structure, any new data is always appended to the end of the stream.
The default method for adding data
This is the simplest way to add data into Redis Streams:
XADD mystream * name Anna
XADD mystream * name Bert
XADD mystream * name Cathy
In this command, XADD is the Redis command, mystream is the name of the stream, Anna, Bert, and Cathy are the names added in each line, and the * operator tells Redis to auto-generate the identifier for each line. This command results in three mystream entries:
1518951481323-0 name Cathy
1518951480723-0 name Bert
1518951480106-0 name Anna
Adding data with user-managed IDs for each entry
Redis gives you an option to maintain your own identifier for each entry (see below). While this may be useful in some cases, it’s usually simpler to rely on auto-generated IDs.
XADD mystream 10000000 name Anna
XADD mystream 10000001 name Bert
XADD mystream 10000002 name Cathy
This results in the following mystream entries:
10000002-0 name Cathy
10000001-0 name Bert
10000000-0 name Anna
Adding data with a maximum limit
You can cap your stream with a maximum number of entries:
XADD mystream MAXLEN 1000000 * name Anna
XADD mystream MAXLEN 1000000 * name Bert
XADD mystream MAXLEN 1000000 * name Cathy
This command evicts older entries when the stream reaches a length of around 1,000,000.
A tip: Redis Streams stores data in the macro nodes of a radix tree. Each macro node has a few data items (typically, in the range of a few tens). Adding an approximate MAXLEN value as shown below avoids having to manipulate the macro node for each insertion. If a few tens of numbers — e.g., whether 1000000 or 1000050 — makes little difference to you, you could optimize your performance by calling the command with the approximation character (~).
XADD mystream MAXLEN ~ 1000000 * name Anna
XADD mystream MAXLEN ~ 1000000 * name Bert
XADD mystream MAXLEN ~ 1000000 * name Cathy
Consume data from a stream with Redis Streams
The Redis Streams structure offers a rich set of commands and features to consume your data in a variety of ways.
Read everything from the beginning of the stream
Situation: The stream already has the data you need to process, and you want to process it all from the beginning.
The command you’ll use for this is XREAD, which allows you to read all or the first N entries from the beginning of the stream. As a best practice, it’s always a good idea to read the data page by page. To read up to 100 entries from the beginning of the stream, the command is:
XREAD COUNT 100 STREAMS mystream 0
Assuming 1518951481323-0 is the last ID of the item you received in the previous command, you can retrieve the next 100 entries by running:
XREAD COUNT 100 STREAMS mystream 1518951481323-1
Consume data asynchronously (via a blocking call)
Situation: Your consumer consumes and processes data faster than the rate at which data is added to the stream.
There are many use cases where the consumer reads faster than the producers add data to your stream. In these scenarios, you want the consumer to wait and be notified when new data arrives. The BLOCK option allows you to specify the length of time to wait for new data:
XREAD BLOCK 60000 STREAMS mystream 1518951123456-1
Here, XREAD returns all of the data after 1518951123456-1. If there’s no data after that, the query will wait for N=60 seconds until fresh data arrives, and then time out. If you want to block this command infinitely, call XREAD as follows:
XREAD BLOCK 0 STREAMS mystream 1518951123456-1
Note: In this example, you could also retrieve data page by page by using the XRANGE command.
Read only new data as it arrives
Situation: You are interested in processing only the new set of data starting from the current point in time.
When you are reading data repeatedly, it’s always a good idea to restart with where you left off. For example, in the previous example, you made a blocking call to read data greater than 1518951123456-1. However, to start with, you may not know the latest ID. In such cases, you can start reading the stream with the $ sign, which tells the XREAD command to retrieve only new data. As this call uses the BLOCK option with 60 seconds, it will wait until there is some data in the stream.
XREAD BLOCK 60000 STREAMS mystream $
In this case, you’ll start reading new data with the $ option. However, you should not make subsequent calls with the $ option. For instance, if 1518951123456-0 is the ID of the data retrieved in previous calls, your next call should be:
XREAD BLOCK 60000 STREAMS mystream 1518951123456-1
Iterate the stream to read past data
Situation: Your data stream already has enough data, and you want to query it to analyze data collected so far.
You could read the data between two entries either in forward or backward direction using XRANGE and XREVRANGE respectively. In this example, the command reads data between 1518951123450-0 and 1518951123460-0:
XRANGE mystream 1518951123450-0 1518951123460-0
XRANGE also allows you to limit the number of items returned with the help of the COUNT option. For example, the following query returns the first 10 items between the two intervals. With this option, you could iterate through a stream as you do with the SCAN command:
XRANGE mystream 1518951123450-0 1518951123460-0 COUNT 10
When you do not know the lower or upper bound of your query, you can replace the lower bound by – and the upper bound by +. For example, the following query returns the first 10 items from the beginning of your stream:
XRANGE mystream - + COUNT 10
The syntax for XREVRANGE is similar to XRANGE, except that you reverse the order of your lower and upper bounds. For example, the following query returns the first 10 items from the end of your stream in reverse order:
XREVRANGE mystream + - COUNT 10
Partition data among more than one consumer
Situation: Consumers consume your data far slower than producers produce it.
In certain cases, including image processing, deep learning, and sentiment analysis, consumers can be very slow when compared to producers. In these cases, you match the speed of data arriving to the data being consumed by fanning out your consumers and partitioning the data consumed by each one.
With Redis Streams, you can use consumer groups to accomplish this. When more than one consumer is part of a group, Redis Streams will ensure that every consumer receives an exclusive set of data.
XREADGROUP GROUP mygroup consumer1 COUNT 2 STREAMS mystream >
Of course, there’s plenty more to learn about how consumer groups work. Redis Streams consumer groups are designed to partition data, recover from disasters, and deliver transaction data safety. I’ll explain all of this in my next article here.
As you can see, it’s easy to get started with Redis Streams. Just download and install Redis 5.0 and dive into the Redis Streams tutorial on the project website.
Roshan Kumar is a senior product manager at Redis Labs. He has extensive experience in software development and technology marketing. Roshan has worked at Hewlett-Packard and many successful Silicon Valley startups including ZillionTV, Salorix, Alopa, and ActiveVideo. As an enthusiastic programmer, he designed and developed mindzeal.com, an online platform hosting computer programming courses for young students. Roshan holds a bachelor’s degree in computer science and an MBA from Santa Clara University.
—
New Tech Forum provides a venue to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to newtechforum@infoworld.com.