






Before you begin your journey as an Apache Spark programmer, you should have a solid understanding of the Spark application architecture and how applications are executed on a Spark cluster. This article closely examines the components of a Spark application, looks at how these components work together, and looks at how Spark applications run on standalone and YARN clusters.
Anatomy of a Spark application
A Spark application contains several components, all of which exist whether you’re running Spark on a single machine or across a cluster of hundreds or thousands of nodes.
Each component has a specific role in executing a Spark program. Some of these roles, such as the client components, are passive during execution; other roles are active in the execution of the program, including components executing computation functions.
The components of a Spark application are:
- the driver
- the master
- the cluster manager
- the executors
They all run on worker nodes, aka workers.
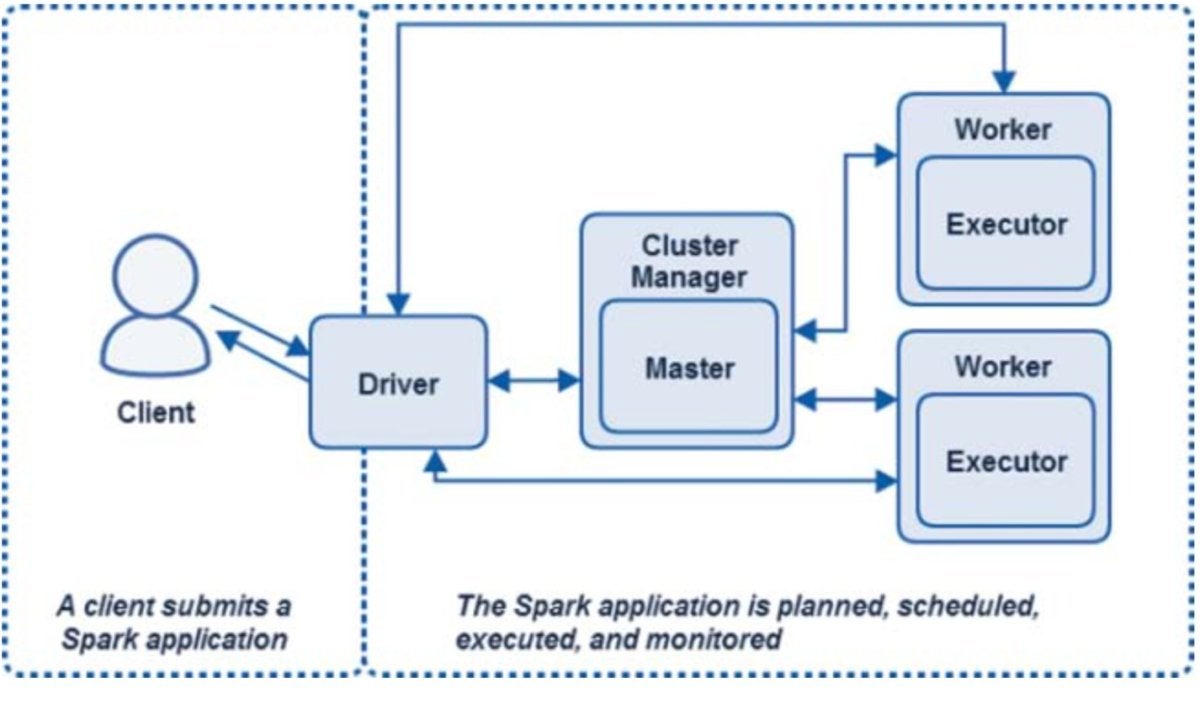
Figure 1 shows all the Spark components in the context of a Spark standalone application.
 Pearson Addison-Wesley
Pearson Addison-Wesley
Figure 1. Spark standalone cluster application components
All Spark components—including the driver, master, and executor processes—run in Java virtual machines. A JVM is a cross-platform runtime engine that can execute instructions compiled into Java bytecode. Scala, which Spark is written in, compiles into bytecode and runs on JVMs.
It is important to distinguish between Spark’s runtime application components and the locations and node types on which they run. These components run in different places using different deployment modes, so don’t think of these components in physical node or instance terms. For example, when running Spark on YARN, there would be several variations of Figure 1. However, all the components pictured are still involved in the application and have the same roles.
Spark driver
The life of a Spark application starts and finishes with the Spark driver. The driver is the process that clients use to submit applications in Spark. The driver is also responsible for planning and coordinating the execution of the Spark program and returning status and/or results (data) to the client. The driver can physically reside on a client or on a node in the cluster, as you will see later.
SparkSession
The Spark driver is responsible for creating the SparkSession. The SparkSession object represents a connection to a Spark cluster. The SparkSession is instantiated at the beginning of a Spark application, including the interactive shells, and is used for the entirety of the program.
Before Spark 2.0, entry points for Spark applications included the SparkContext, used for Spark core applications; the SQLContext and HiveContext, used with Spark SQL applications; and the StreamingContext, used for Spark Streaming applications. The SparkSession object introduced in Spark 2.0 combines all these objects into a single entry point that can be used for all Spark applications.
Through its SparkContext and SparkConf child objects, the SparkSession object contains all the runtime configuration properties set by the user, including configuration properties such as the master, application name, and number of executors. Figure 2 shows the SparkSession object and some of its configuration properties in a pyspark shell.
 Pearson Addison-Wesley
Pearson Addison-Wesley
Figure 2. SparkSession properties
The code below demonstrates how to create a SparkSession in a noninteractive Spark application, such as a program submitted using spark-submit.
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.master("spark://sparkmaster:7077") \
.appName("My Spark Application") \
.config("spark.submit.deployMode", "client") \
.getOrCreate()
numlines = spark.sparkContext.textFile("file:///opt/spark/licenses") \
.count()
print("The total number of lines is " + str(numlines))
Application planning
One of the main functions of the driver is to plan the application. The driver takes the application processing input and plans the execution of the program. The driver takes all the requested transformations(data manipulation operations) and actions (requests for output or prompts to execute programs) and creates a directed acyclic graph (DAG) of nodes, each representing a transformational or computational step.
A Spark application DAG consists of tasks and stages. A task is the smallest unit of schedulable work in a Spark program. A stage is a set of tasks that can be run together. Stages are dependent on one another; in other words, there are stage dependencies.
In a process scheduling sense, DAGs are not unique to Spark. For example, they are used in other big data ecosystem projects, such as Tez, Drill, and Presto for scheduling. DAGs are fundamental to Spark, so it is worth being familiar with the concept.
Application orchestration
The driver also coordinates the running of stages and tasks defined in the DAG. Key driver activities involved in the scheduling and running of tasks include the following:
- Keeping track of available resources to execute tasks.
- Scheduling tasks to run “close” to the data where possible (the concept of data locality).
Other functions
In addition to planning and orchestrating the execution of a Spark program, the driver is also responsible for returning the results from an application. These could be return codes or data in the case of an action that requests data to be returned to the client (for example, an interactive query).
The driver also serves the application UI on port 4040, as shown in Figure 3. This UI is created automatically; it is independent of the code submitted or how it was submitted (that is, interactive using pyspark or noninteractive using spark-submit).
 Pearson Addison-Wesley
Pearson Addison-Wesley
Figure 3. Spark application UI
If subsequent applications launch on the same host, successive ports are used for the application UI (for example, 4041, 4042, and so on).
Spark workers and executors
Spark executors are the processes on which Spark DAG tasks run. executors reserve CPU and memory resources on slave nodes, or workers, in a Spark cluster. An executor is dedicated to a specific Spark application and terminated when the application completes. A Spark program normally consists of many executors, often working in parallel.
Typically, a worker node—which hosts the executor process—has a finite or fixed number of executors allocated at any point in time. Therefore, a cluster—being a known number of nodes—has a finite number of executors available to run at any given time. If an application requires executors in excess of the physical capacity of the cluster, they are scheduled to start as other executors complete and release their resources.
As mentioned earlier, JVMs host Spark executors. The JVM for an executor is allocated a heap, which is a dedicated memory space in which to store and manage objects.
The amount of memory committed to the JVM heap for an executor is set by the property spark.executor.memory or as the --executor-memory argument to the pyspark, spark-shell, or spark-submit commands.
Executors store output data from tasks in memory or on disk. It is important to note that workers and executors are aware only of the tasks allocated to them, whereas the driver is responsible for understanding the complete set of tasks and the respective dependencies that comprise an application.
By using the Spark application UI on port 404x of the driver host, you can inspect executors for the application, as shown in Figure 4.
 Pearson Addison-Wesley
Pearson Addison-Wesley
Figure 4. Executors tab in the Spark application UI
For Spark standalone cluster deployments, a worker node exposes a user interface on port 8081, as shown in Figure 5.
 Pearson Addison-Wesley
Pearson Addison-Wesley
Figure 5. Spark worker UI
The Spark master and cluster manager
The Spark driver plans and coordinates the set of tasks required to run a Spark application. The tasks themselves run in executors, which are hosted on worker nodes.
The master and the cluster manager are the central processes that monitor, reserve, and allocate the distributed cluster resources (or containers, in the case of YARN or Mesos) on which the executors run. The master and the cluster manager can be separate processes, or they can combine into one process, as is the case when running Spark in standalone mode.
Spark master
The Spark master is the process that requests resources in the cluster and makes them available to the Spark driver. In all deployment modes, the master negotiates resources or containers with worker nodes or slave nodes and tracks their status and monitors their progress.
When running Spark in Standalone mode, the Spark master process serves a web UI on port 8080 on the master host, as shown in Figure 6.
 Pearson Addison-Wesley
Pearson Addison-Wesley
Figure 6. Spark master UI
Cluster manager
The cluster manager is the process responsible for monitoring the worker nodes and reserving resources on these nodes on request by the master. The master then makes these cluster resources available to the driver in the form of executors.
As noted earlier, the cluster manager can be separate from the master process. This is the case when running Spark on Mesos or YARN. In the case of Spark running in standalone mode, the master process also performs the functions of the cluster manager. Effectively, it acts as its own cluster manager.
A good example of the cluster manager function is the YARN ResourceManager process for Spark applications running on Hadoop clusters. The ResourceManager schedules, allocates, and monitors the health of containers running on YARN NodeManagers. Spark applications then use these containers to host executor processes, as well as the master process if the application is running in clustermode.
Spark applications using the standalone scheduler
In Chapter 2, “Deploying Spark,” I explained the standalone scheduler as a deployment option for Spark. There, I deployed a fully functional multinode Spark standalone cluster in one of the exercises in Chapter 2. As noted earlier, in a Spark cluster running in standalone mode, the Spark master process performs the cluster manager function as well, governing available resources on the cluster and granting them to the master process for use in a Spark application.
Spark applications running on YARN
Hadoop is a very popular and common deployment platform for Spark. Some industry pundits believe that Spark will soon supplant MapReduce as the primary processing platform for applications in Hadoop. Spark applications on YARN share the same runtime architecture but have some slight differences in implementation.
ResourceManager as the cluster manager
In contrast to the Standalone scheduler, the cluster manager in a YARN cluster is the YARN ResourceManager. The ResourceManager monitors resource usage and availability across all nodes in a cluster. Clients submit Spark applications to the YARN ResourceManager. The ResourceManager allocates the first container for the application, a special container called the ApplicationMaster.
ApplicationMaster as the Spark master
The ApplicationMaster is the Spark master process. As the master process does in other cluster deployments, the ApplicationMaster negotiates resources between the application driver and the cluster manager (or ResourceManager in this case); it then makes these resources (containers) available to the driver for use as executors to run tasks and store data for the application.
The ApplicationMaster remains for the lifetime of the application.
Deployment modes for Spark applications running on YARN
Two deployment modes can be used when submitting Spark applications to a YARN cluster: client mode and cluster mode. Let’s look at them now.
Client mode
In client mode, the driver process runs on the client submitting the application. It is essentially unmanaged; if the driver host fails, the application fails. Client mode is supported for both interactive shell sessions (pyspark, spark-shell, and so on) and noninteractive application submission (spark-submit). The code below shows how to start a pyspark session using the client deployment mode.
$SPARK_HOME/bin/pyspark \
--master yarn-client \
--num-executors 1 \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1
# OR
$SPARK_HOME/bin/pyspark \
--master yarn \
--deploy-mode client \
--num-executors 1 \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1
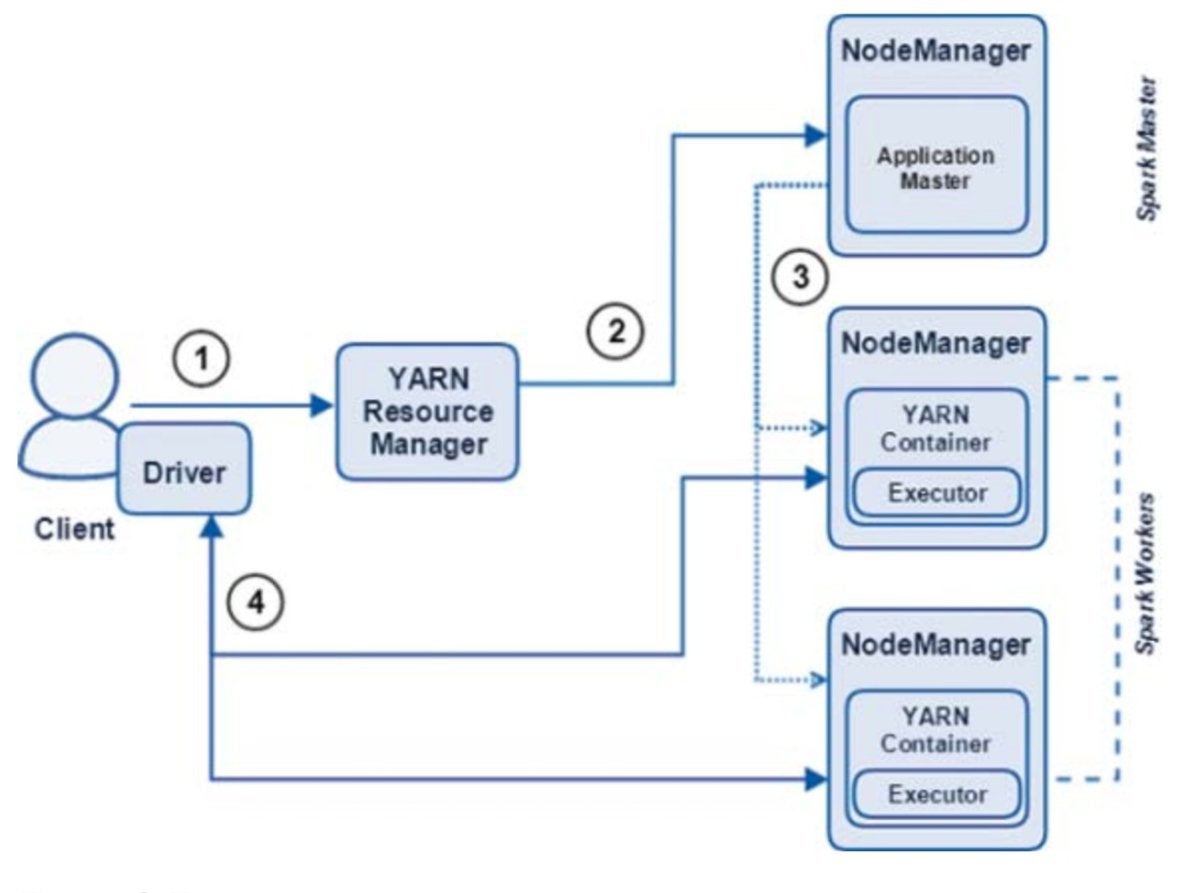
Figure 7 provides an overview of a Spark application running on YARN in client mode.
 Pearson Addison-Wesley
Pearson Addison-Wesley
Figure 7. Spark application running in YARN client mode
The steps shown in Figure 7 are:
- The client submits a Spark application to the cluster manager (the YARN ResourceManager). The driver process, SparkSession, and SparkContext are created and run on the client.
- The ResourceManager assigns an ApplicationMaster (the Spark master) for the application.
- The ApplicationMaster requests containers to be used for executors from the ResourceManager. With the containers assigned, the executors spawn.
- The driver, located on the client, then communicates with the executors to marshal processing of tasks and stages of the Spark program. The driver returns the progress, results, and status to the client.
The client deployment mode is the simplest mode to use. However, it lacks the resiliency required for most production applications.
Cluster mode
In contrast to the client deployment mode, with a Spark application running in YARN Cluster mode, the driver itself runs on the cluster as a subprocess of the ApplicationMaster. This provides resiliency: If the ApplicationMaster process hosting the driver fails, it can be re-instantiated on another node in the cluster.
The code below shows how to submit an application by using spark-submit and the YARN cluster deployment mode. Because the driver is an asynchronous process running in the cluster, cluster mode is not supported for the interactive shell applications (pyspark and spark-shell).
$SPARK_HOME/bin/spark-submit \
--master yarn-cluster \
--num-executors 1 \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1
$SPARK_HOME/examples/src/main/python/pi.py 10000
# OR
$SPARK_HOME/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--num-executors 1 \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1
$SPARK_HOME/examples/src/main/python/pi.py 10000
Figure 8 provides an overview of a Spark application running on YARN in cluster mode.
 Pearson Addison-Wesley
Pearson Addison-Wesley
Figure 8. Spark application running in YARN cluster mode
The steps shown in Figure 8 are:
- The client, a user process that invokes
spark-submit, submits a Spark application to the cluster manager (the YARN ResourceManager). - The ResourceManager assigns an ApplicationMaster (the Spark master) for the application. The driver process is created on the same cluster node.
- The ApplicationMaster requests containers for executors from the ResourceManager. executors are spawned in the containers allocated to the ApplicationMaster by the ResourceManager. The driver then communicates with the executors to marshal processing of tasks and stages of the Spark program.
- The driver, running on a node in the cluster, returns progress, results, and status to the client.
The Spark application web UI, as shown previously, is available from the ApplicationMaster host in the cluster; a link to this user interface is available from the YARN ResourceManager UI.
Local mode revisited
In local mode, the driver, the master, and the executor all run in a single JVM. As noted earlier in this chapter, this is useful for development, unit testing, and debugging, but it has limited use for running production applications because it is not distributed and does not scale. Furthermore, failed tasks in a Spark application running in local mode are not re-executed by default. You can override this behavior, however.
When running Spark in local mode, the application UI is available at http://localhost:4040. The master and worker UIs are not available when running in local mode.