





Researchers have released an open source neural network system for performing language translations that could be an alternative to proprietary, black-box translation services.
Open Source Neural Machine Translation (OpenNMT) merges work from researchers at Harvard with contributions from long-time machine-translation software creator Systran. It runs on the Torch scientific computing framework, which is also used by Facebook for its machine learning projects.
Ideally, OpenNMT could serve as an open alternative to closed-source projects like Google Translate, which recently received a major neural-network makeover to improve the quality of its translation.
But the algorithms aren't the hard part; it’s coming up with good sources of data to support the translation process—which is where Google and the other cloud giants that provide machine translation as a service have the edge.
Speaking in tongues
OpenNMT, which uses the Lua language to interface with Torch, works like other products in its class. The user prepares a body of data that represents the two language pairs to be translated—typically the same text in both languages as translated by a human translator. After training OpenNMT on this data, the user can then deploy the resulting model and use it to translate texts.
Torch can take advantage of GPU acceleration, which means the training process for OpenNMT models can be sped up a great deal on any GPU-equipped system. That said, the training process can take a long time—“sometimes many weeks.” But the training process can be snapshotted and resumed on demand if needed. If you want to use the trained model on a CPU rather than a GPU, you’ll need to convert the model to work in CPU mode. OpenNMT provides a tool to do exactly that.
A live demo provided by Systran claims to use OpenNMT in conjunction with Systran’s own work. For common language pairs like English/French, the translations are quite accurate. For pairs where there’s likely to be a smaller body of texts available, or where the language pairs don’t map as precisely to each other—say, English/Japanese—the translations are a little more stilted and imprecise. In one sample Japanese sentence, the Systran demo mistook the word “seagulls” in Japanese for “hanging scrolls;” Google Translate correctly translated it.
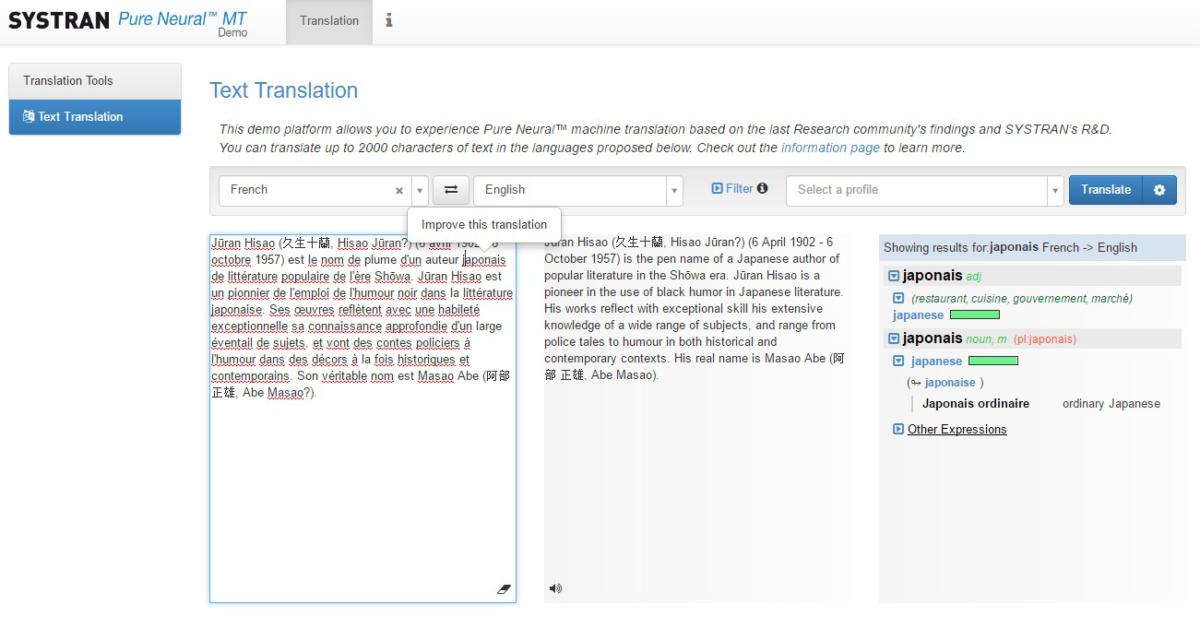 IDG
IDG An online demo of Systran's professional machine translation product. Systran uses OpenNMT's technology in conjunction with proprietary innovations to power this system.
Words, words, words
The most crucial element that OpenNMT does not yet supply is pretrained language model data. A link to Example Models on the GitHub site for the project currently yields an error. Presumably in time this will feature sample data that can be used to benchmark the system or get a feel for how the training and deployment process works. But it wont' likely include data that can be used in a production environment.
This limits how useful OpenNMT is out of the box, since the model data is at least as crucial for machine translation as the algorithms themselves. Translating between language pairs requires parallel corpora, or texts in both languages that are closely matched to each other on a sentence-by-sentence or phrase-by-phrase level, and can be trained to yield models in products like OpenNMT.
Many corpora are freely available, but require cobbling together by hand to be useful to the average developer. Vendors like Google—and IBM, with its Language Translator system on Watson—have an advantage in that they can easily build corpora with their other services. Google can automatically harvest massive amounts of constantly refreshed language data by way of its search engine.
Still, OpenNMT is bound to be useful to those who want to build new functionality on top of OpenNMT’s modeling and training code, and don’t want to be dependent on a behind-the-API algorithm like Google’s to do it.